
Redis知识巩固
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker. Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
一、Redis 安装
安装前提:Linux 系统 ubuntu 18.04 / Redis 版本:6.2.5
1、检查系统是否安装了gcc 编译器。如果已经安装了 则会显示gcc 的版本号信息,如果没有安装,则使用系统的包管理器安装。
1 | 检查版本 |
2、在Redis官网下载Redis压缩包并解压。
1 | wget https://download.redis.io/releases/redis-6.2.5.tar.gz |
3、进入解压后的Redis目录,编译安装Redis。
1 | cd redis-6.2.5 |
4、Redis 默认安装在Linux的usr/local/bin 目录下。
5、启动Redis 。(这种方式是在前台运行)
1 | cd /usr/local/bin |
二、Redis 基础命令
Redis的命令文档
1 | 选择Redis数据库 一共0到15 16个数据库,默认使用0数据库。 |
三、Redis 五大常用数据类型
1 String
String是Redis常用的基本类型,对应的格式是一个key对应一个value,String是二进制安全的,意味着string可以存储任意的类型,包括图片或者序列化的对象。一个Redis中String类型value的值最多可以是512M。
1.1 String 的基本命令
1 | 设置key value |
1.2 String 的数据结构
String 的数据结构为简单的动态的字符串(Simple Dynamic String 缩写SDS),是可以修改的字符串,采用预分配冗余空间的方式,来减少内存的频繁分配。
2 List
List 是简单的字符串列表,按照插入的顺序排序,可以添加一个元素到字符串的头部或者尾部。他的底层实际上十个双向链表,对两端的操作性能很高,通过索引下标操作中间的节点性能比较差。
2.1 List的基本命令
1 | 从左边插入一个或者多个值, 使用头插法插入,类似栈的先进后出 |
2.2 List 的数据结构
List 的数据结构为quicklist。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,即压缩列表。他将所有的元素紧挨着一块存储,分配的是一块连续的内存。
当数据量比较多的时候,才会改为quicklist,因为普通的链表需要的附加的指针空间更大,会比较浪费空间。
比如列表里面存储的只是Int的类型的数据,结构上还需要两个额外的指针:prev和next。
Redis 将链表和ziplist结合起来组成了quicklist,也就是将多个ziplist 使用双向指针串起来,这样既满足了插入删除性能,又不会出现太大的空间冗余。如上图所示。
3 Set
3.1 Set的基本命令
1 | 将一个或者多个member元素添加到集合key中,已经存在的member元素将会被忽略 |
3.2 Set 的数据结构
Set 的数据结构是dict字典,字典是使用哈希表实现的。所有的value 都指向同一个内部的值。
4 Hash
4.1 Hash的基本命令
Redis 的Hash是一个键值对集合,是一个String类型的field和value 的映射表,Hash特别适合存储对象。
1 | 给key集合中的field 键赋值value |
4.2 Hsh 的数据结构
Hash 类型对应的数据机构有两种:ziplist (压缩列表) 和 hashlist(哈希列表) ,当field-value 的长度较短且个数较少的时候,使用ziplist,否则使用hashlist。
5 ZSet
Redis的有序集合和Set 类似,是一个没有重复元素的字符串集合,不同之处是有序集合的每个成员都关联了一个评分,这个评分被用来按照从最低到最高的方式排序集合中的成员,集合的成员是唯一的,但是评分可以重复。
因为元素是有序的,所以可以很快的根据评分或者次序来获得一个范围的元素。
访问集合中的元素也是非常快的,因此能够使用有序集合作为一个没有重复成员的智能列表。
5.1 ZSet 的基命令
1 | 将一个或者多个member元素及其其score值加入到有序集key当中 |
5.2 Zset 的数据结构
SortedSet 是Redis的一个特别的数据结构,他的底层使用了两个数据结构。
- hash,hash 的作用就是关联元素value和权重score,保障元素value的唯一性们可以通过元素value找到相应的score。
- 跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素的列表。
6 Bitmaps
BItmaps 本身并不是一种数据类型,实际上他就是字符串,key-value ,但是他可以对字符串进行位操作。
Bitmaps 单独提供了一套目命令,所以在Redis 中使用Bitmaps和使用字符串方法不一样,可以吧Bitmaps想象成一个以位为单位的数组,数组的每个单元只能存储0和1数组的下标在Bitmaps中叫偏移量。
6.1 Bitmaps 的基本命令
1 | 设置Bitmaps 中某个偏移量的值 0 或 1, offset的偏移量从0开始 |
7 HyperLogLog
7.1 HyperLogLog 的基本命令
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog的优点是在输入元素的数量或者体积非常大的时候计算基数所需要空间总是固定的,并且是很小的。
在Redis里面每个HyperLogLog 键只需要花费12KB内存,就可以计算接近2^64个不同的基数,这和计算基数时元素越多消耗内存就越多的集合形成鲜明对比。
但是HyperLogLog 只会根据输入元素计算基数,而不会存储输入数据本身,所以HyperLogLog并不能像集合那样返回输入的各个元素。
什么是基数?
比如数据集:{1、3、5、7、5、7、9} 那么这个数据集的基数就是:{1、3、5、7、9} 基数(不重复元素)为5。基数估计 就是在误差可以收的范围内快速计算基数。
1 | 添加指定元素到 HyperLogLog 中 |
8 Geospatial
Redis 3.2 中增加对GEO类型的支持,GEO是Geographic地理信息的缩写。该类型就是元素的二维坐标,在地图上就是经纬度,Redis基于该类型提供了经纬度设置,范围查询。距离查询。经纬度Hash等操作。
8.1 Geospatial的基本命令
1 | 添加地理位置 经度 纬度 名称, 两级无法添加,一般会下载城市经纬度数据,直接导入。有效的经度从-180 到180 纬度 -85.05112878 到 85.05112878 ,超出范围会返回错误。 |
四、Redis 的事务操作
Redis 的事务 是一个单独的隔离的操作,事务中所有的命令都会序列化、按顺序的执行,事务在执行过程中,不会被其他的客户端发送过来的命令请求打断。
Redis的事务的主要作用就是串联多个命令防止别的命令插队。
从输入Multi 开始,输入的命令都会依次进入命令队列中,但不会执行,直到输入Exec后,Redis会将之前的命令队列中的命令依次执行。组队的过程中可以通过Discard来放弃组队。
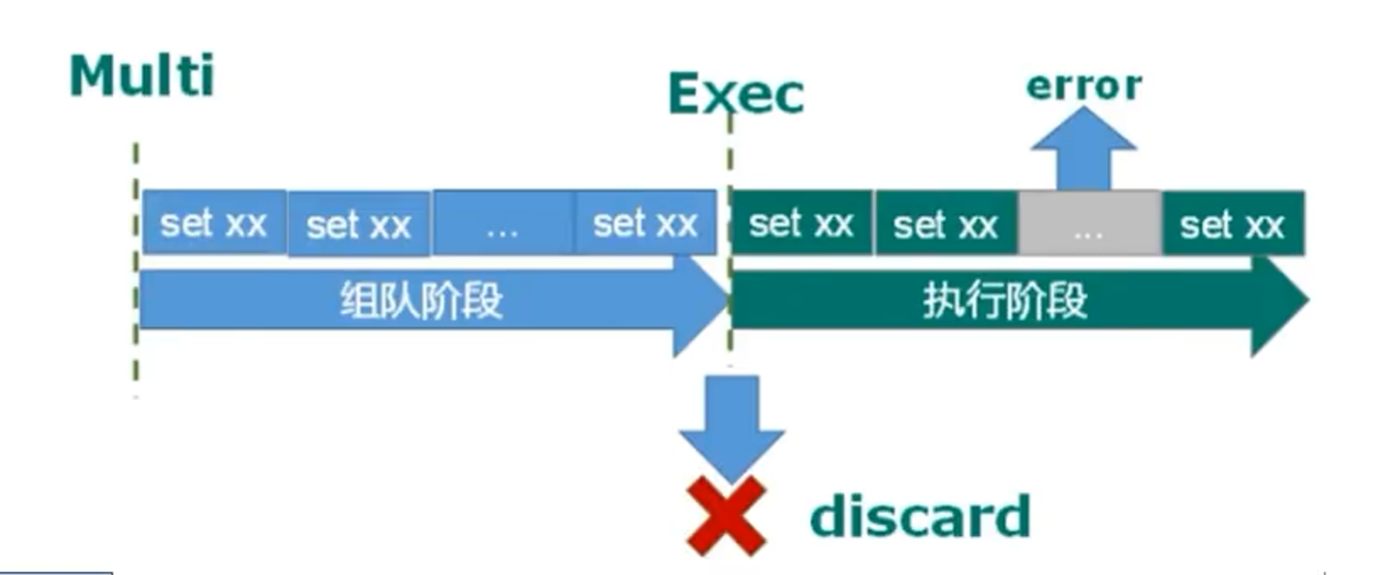
1 Redis 事务的错误处理
1.1 组队中某个命令出现了报告错误,执行时所有的队列都会被取消。
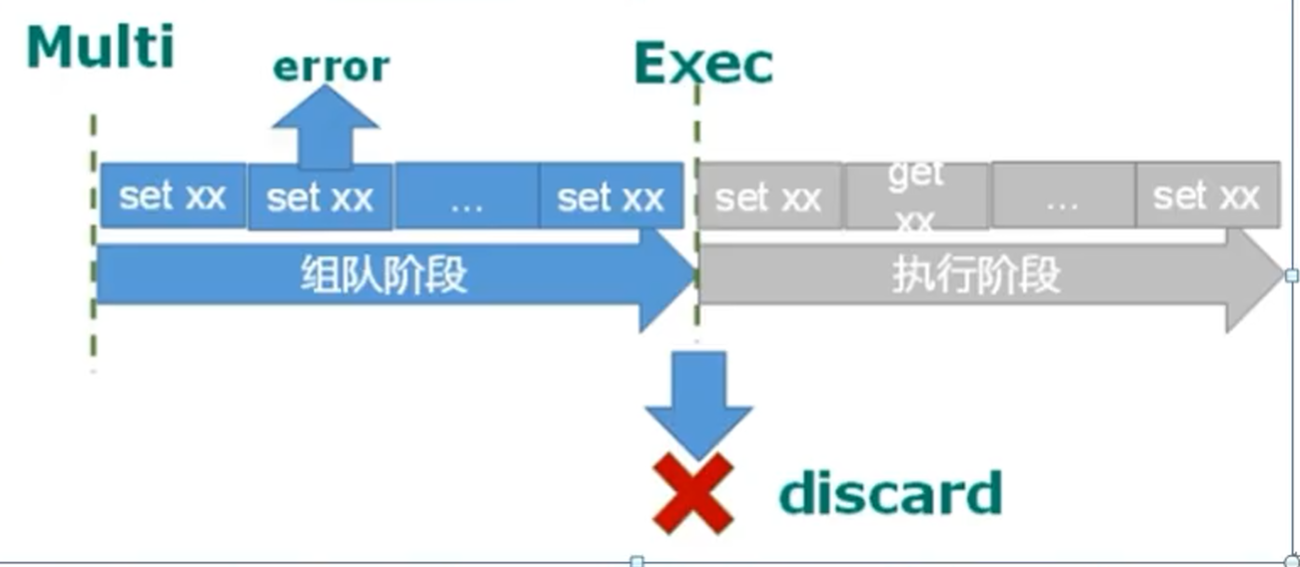
1.2 组队中所有的命令成功,执行时只有失败的命令失败,其他的命令成功。
1.3 Redis的事务冲突,以及解决办法。
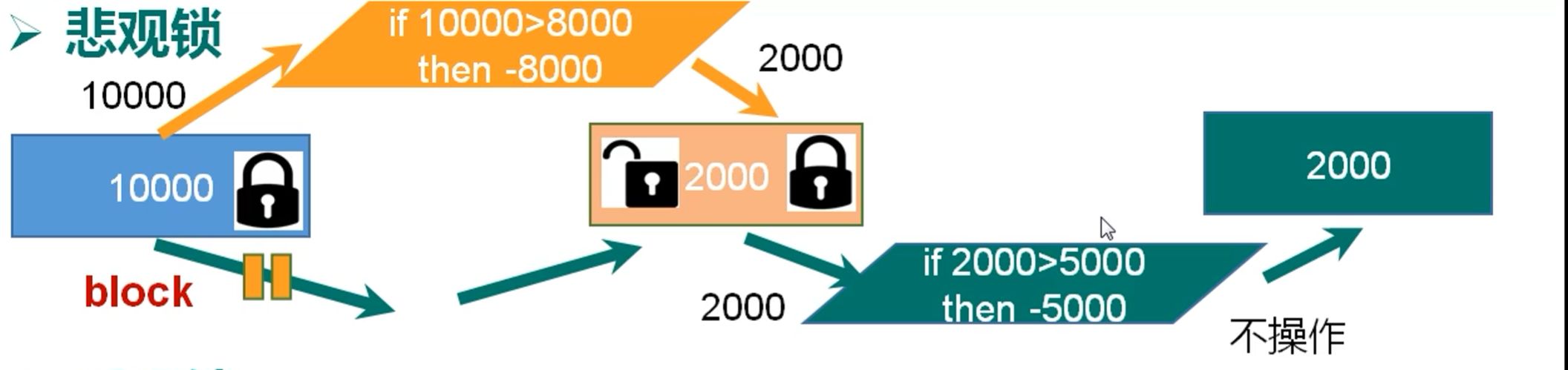
1.3.1 悲观锁
每次去获取数据都认为别人会修改,所以每次拿数据的时候都会上锁,这样别人就只能等到锁释放才能能拿到数据。传统的关系型数据库很多地方都用到了悲观锁:比如行锁、表锁、读锁、写锁等。
1.3.2 乐观锁
每次拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有更新这数据,可以使用版本号等机制。乐观锁适用于多读的场景,这样可以以高吞吐量,Redis 就是利用这用check-and-set的机制实现事务的。实际应用场景:例如买票,很多人都可以抢到,但是付款只有一个人可以付款成功。
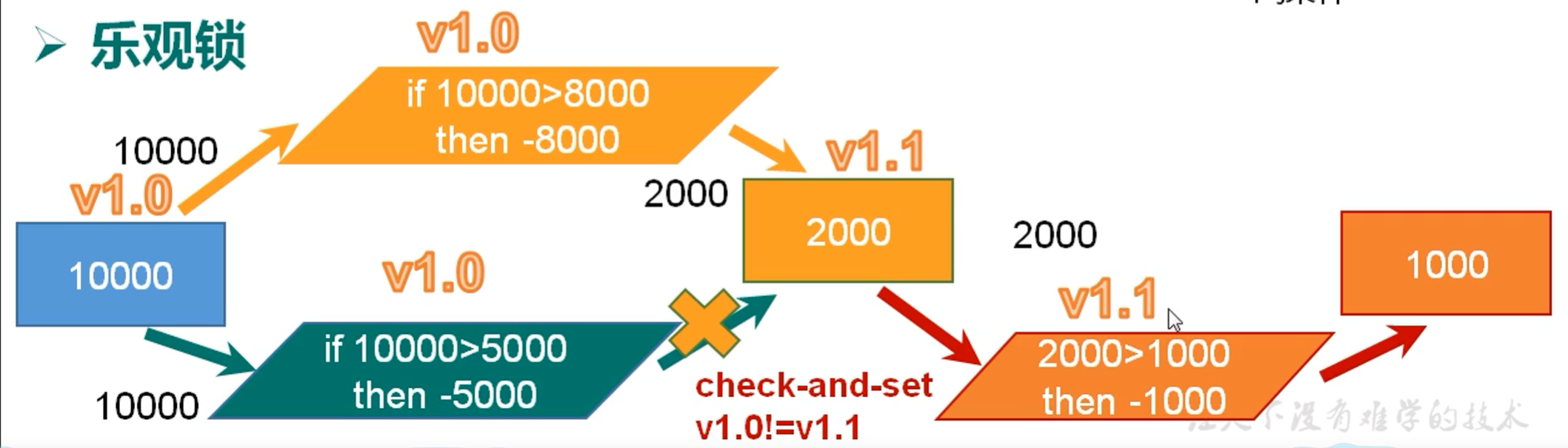
在Redis 中使用乐观锁
在执行Multi 之前先执行 watch key 可以监听一个或者多个key,如果事务执行之前这个key被其他的命令所修改,那么事务将会被打断。
1 | 给Redis加乐观锁 |
1.4 Redis 事务的三特性
1.4.1单独的隔离操作
事务中所有的命令都会序列化,按照顺序执行,事务在执行过程中没不会被其他的可短短发送来的命令请求打断。
1.4.2 没有隔离级别的概念
队列中的命令没有提交之前都不会被实际的执行,因为事务提交之前(exec)任何指令都不会被执行。
1.4.3 不保证原子性
事务中如果有一天命令执行失败,其他的命令仍然会被执行,不会回滚。
五、Redis 的持久化机制
1 RDB (Redis Database) 方式
在指定时间间隔内将内存中的数据集快照写入磁盘,也就是快照,它恢复是将快照文件直接读到内存里面。(在Redis 的配置文件内设置时间间隔)RDB 默认开启。
备份是如何执行的:
Redis 会单独的创建一个fork子进程来持久化,会先将数据写入一个临时文件中,等持久化过程都结束了,在用这个临时文件替换上次持久化的文件,整个过程主进程是不进行任何IO操作的,这就确保了极高的性能,如果需要大规模的数据的恢复,且对于数据的完整性要求不那么敏感,那么RDB的方式要比AOF的方式更加的额高效,RDB的缺点就是最后一次持久化的数据可能会丢失。
fork的作用就是复制一个与当前进程一样的进程,新的进程的所有的数据(变量,程序计数器等)都和原进程一样,但是是一个全新的进程,并作为原进程的子进程。
1 | 配置文件解释 |
RDB的优势:
- 适合大规模数据的恢复。
- 对数据完整性和一致性要求不高时使用。
- 节省磁盘空间。
- 回恢复度快。
RDB的劣势:
- 在写入临时快照的时候,数据被克隆了一份,大致两倍的膨胀性需要考虑。
- 虽然Redis在fork时使用了写时拷贝技术,但是如果数据量庞大还是比较消耗性能。
- 在备份周期在一定时间间隔内做一次备份,所以如果Redis以外关掉,就会丢失最后一次快照的修改。
RDB的备份恢复:
默认Redis启动会自动将Redis的快照文件(dump.rdb)读取到内存中。手动恢复的话只需要将快照文件复制到Redis启动目录下。
2 AOF(Append Only File)方式
以日志的形式来记录每个写操作(增量保存),将Redis执行过的所有写/修改/删除指令记录下来(读操作不记录),只许追加文件但是不可以改文件,Redis启动之初,会自动读取范围见重新构建数据,换言之Redis重启的话就会根据日志文件的内容将写指令重头到尾在执行一遍,以完成数据的恢复工作。AOF默认不开启。
开启AOF:
1 | 默认为no 不开启, 将其改为yes 开启。 |
如果RDB和AOF同时开启,Redis 默认会读取AOF的配置文件来恢复数据。
AOF 异常修复:
如果遇到AOF文件损坏,通过 redis-check-aof –fix appendonly.aof 进行恢复。
AOF的同步频率设置:
1 | 设置AOF的同步频率 。 |
Rewrite 压缩
AOF 采用文件追加方式,文件会越来越大,为避免出现此种情况,新增了重写机制,当AOF文件的大小超过设置的阈值时,Redis回启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集,可以使用命令bgrewriteaof。
重写的原理:
AOF文件持续增长而过大时, 会fork 出一条新的进程将文件重写(也是先写临时文件最后在rename)Redis4.0后的版本重写,实际上就是把RDB的快照,以二进制的形式附在新的aof的头部,作为已有的历史数据,替换掉原来的流水操作。
AOF持久化的流程:
- 客户端的请求命令会被append追加到AOF的缓冲区内。
- AOF缓冲区根据AOF持久化策略(always/everysec/no)将操作sync同步到磁盘中的.aof文件中去。
- AOF文件大小超过重写策略或者手动重写时,会对AOF文件rewrite重写,压缩AOF文件容量。
六、Redis主从复制
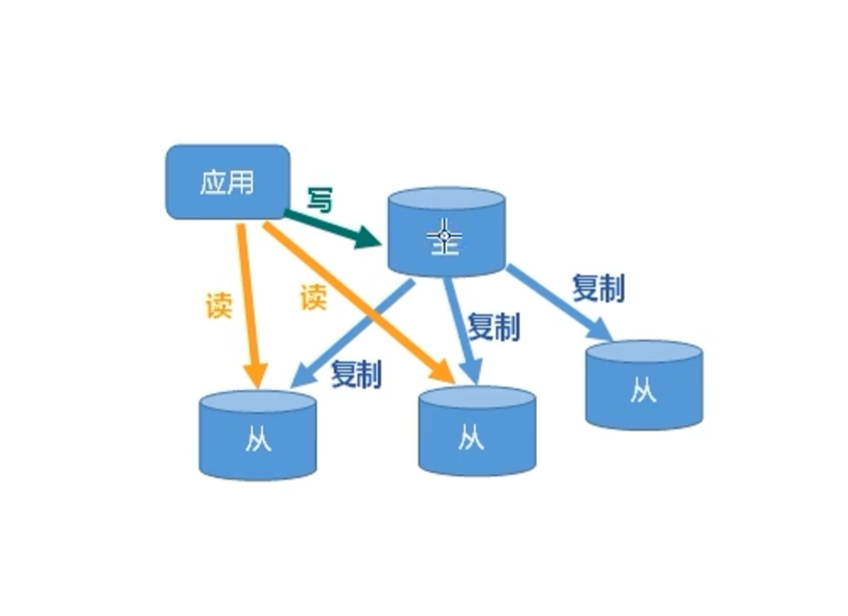
1 | Redis 主从复制配置文件设置 |
1 主从复制的原理:
- 当从服务器连接上主服务器上以后,从服务器向主服务器发送数据同步消息即一个sync命令。
- 主服务器接到从服务器送过来的同步消息,把主服务器的数据进行持久化,把RDB文件发送到从服务器,从服务器拿到RDB进行读取。(从服务器主动请求同步)
- 全量复制:从服务器在接受数据库数据后将其存盘并加载到内存中。
- 增量复制:主服务器将新的所有收集到的修改的命令依次传输给从服务器完成同步。
2 主从复制之薪火相传
Redis 主从模式为 一个主,其他的为从。其中第三个从为第二个从的主,类似于排队的节点,每一节点都是前面的从。也可以多个从节点。
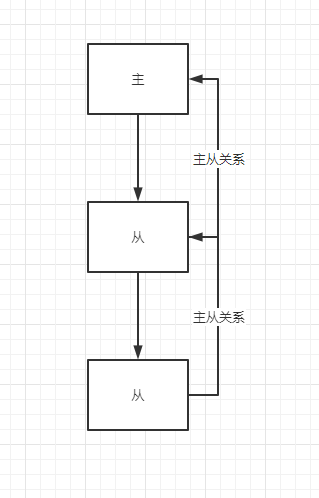
1 | 配置方法: |
3 Redis主从之反客为主
反客为主在薪火相传的基础上给某个从服务器加上能够变为主服务器的命令。使其能够在主服务器挂掉的时候充当主服务器。
1 | 若果想让从服务器在主服务器挂掉之后自动变为主服务器设置方法: 需要手动操作,全自动实现 需要使用哨兵模式 |
4 Redis主从之哨兵模式
配置哨兵模式:
定义配置文件 senttinel.conf (文件名不能错) 文件内容:
1 | mymaster 是为监控对象起的名称, 1 代表至少有多少个哨兵同意迁徙的数量。 |
哨兵故障恢复:
从下线的主服务器的从服务器中挑选一个将其转成主服务器。选择的条件依次为:1. 优先级最靠前的。2. 选择偏移量最大的,3. 选择runid 最小的。
挑选出新的主服务器后sentinel 向原先的主服务器的从服务器发送slaveof 命令,复制新的master,当已经下线的主服务器上线时,sentinel 向其发送slaveof 命令让其成为新主的从。
优先级在Redis.conf 中默认:replica-priority 100 值越小 优先级越高。
偏移量是指获取原主机数据最全的。
每个Redis示例启动后都会随机生成一个40位runid。
七、Redis 集群
Redis 的主从模式,薪火相传。主机宕机,会导致IP的地址变化,应用程序中配置需要修改对应主机啊的地址没端口等信息。之前通过代理主机来解决,Redis 3.0 提供了解决方案,就是无中心化集群方案。
Redis 集群实现了对Redis的水平扩容,即启动N个Redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区,来提供一定程度的可用性,:即使集群中有部分节点失效或者无法进行通讯,集群也能够继续处理命令请求。
1 Redis 集群配置
1 | 包含redis主配置文件 |
以上配置生成了Redis的集群节点,但是还没有将每个节点相结合。以下操作将各个节点结合配置为集群。
1 | 如果是低版本Redis需要安装ruby环境,此版本不需要安装。 |
设置成功如下图所示: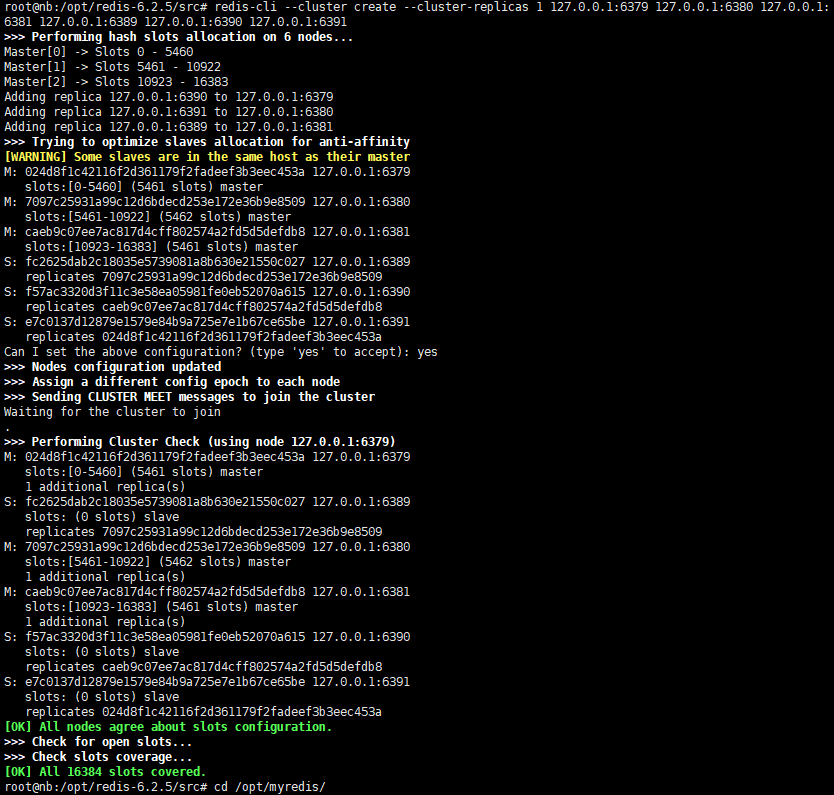
2 Redis 集群连接
1 | 集群连接 |
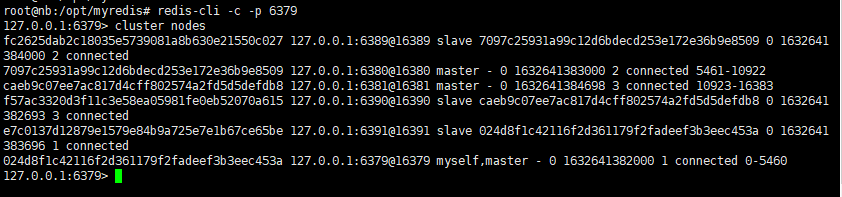
Redis 如何分配至少三个主节点?
首先分配原则尽量保证,每个主数据库运行在不同的IP地址中,每个从库和主库不在同一个IP地址中。
什么是slots?
当Redis集群设置成功后会提示 : All 16384 slots covered,代表一个集群包含16384个插槽,数据库的每个键都会存储到这些个插槽中去,集群使用公式 CRC16(key)%16384 来计算key属于那个插槽,其中CRC16(key) 用于计算key的CRC16校验和。
1 | 计算集群的中的key的个数 |
3 故障恢复
Redis 集群中的某个主服务宕机,他的从服务器会直接成为主服务器,来保持运行。(通过配置文件的失联时间来判断是和否能够正常使用:cluster-node-timeout 15000)
如果Redis的集群中的某个节点的主从全部挂掉,他的情况 需要根据配置文件来说明:
- 如果配置文件中的
cluster-require-full-coverage的值为yes, 则整个集群都挂掉。 - 如果值为
no则该插槽服务挂掉,无法写入读取数据,但是不会影响其他的集群节点。
 微信
微信 支付宝
支付宝



