
MySQL事务与锁机制
什么是事务
MySQL支持事务的储引擎:InnoDB
事务是一条或者一组SQL操作语句。
事务的四大特性:A (atomicity)、C(consistency)、I(isolation)、D(durability)。
满足以上特性的事务操作,才能被称作完整的事务。
事务的四大特性
A(atomicity)原子性 :指一个事务中的所有的操作,要么全部完成,要么全部失败回滚。即像化学中的原子一样是最小单位,不能被分割 。在数据库中是由undo Log(回滚日志) 来实现的。
D(Durability)持久性:事务结束之后对数据的改变是永久的,不会因为外界的干扰而导致数据更改。在数据库中是由redo Log 来实现的。
I(Isolation)隔离性:数据库允许多个事务并发的对数据库同时操作,隔离性可以防止多个事务并发执行而导致的数据不一致。隔离又分为多个隔离级别。在数据库中是由即基于锁的并发控制LBCC(Lock-Based Concurrent Control)+ 多版本并发控制(MVCC)实现的。
C(Consistency)一致性:事务开始前后没数据没有被破坏,开始前后的数据符合预期。
原子性、持久性、隔离性都是为了保证数据的一致性。
事务并发会出现的问题
事务的并发在没有隔离性控制的情况下会出现读一致性的问题
1、脏读:在一个事务中前后两次查询(针对同一条记录)得到的不一样的结果是由于其读取到其他的事务未提交的数据,这种情况叫做脏读。(未在磁盘中持久化,未提交的数据称为脏数据,所以称为脏读。)
2、不可重复读:在一个事务中前后两次查询(针对同一条记录)得到的不一样的结果是由于其读取到其他的事务已经提交的数据,这种情况叫不可重复读。
3、幻读:在一个事务中前后两次查询得到了不一样的结果数,是由于其读取到其他的事务已经提交的新的(新插入的)数据,这种情况叫幻读。
事务的四种隔离级别
针对以上的事务的并发出现的问题,MySQL给出了四种隔离级别:
1、Read Uncommitted (读未提交) :未解决事务的并发问题,事务提交的数据对于其他事务也是可见的会出现脏读。
2、Read Committed (读已提交):解决了脏读的问题,一个事务开始之后只能看到已提交的事务的所做的修改,但是会出现不可重复读的问题。
3、Repeatable Read(可重复读):解决不可重复读问题,在同一个事务中,多次读取同样的数据结果是一样的,这种隔离级别解决幻读的问题。
4、Serializable(串行化):解决所有的问题,最高的隔离级别,让事务强制串行化执行。
在MySQL的InnoDB的存储引擎中实现的隔离级别如下图所示:(全部解决)
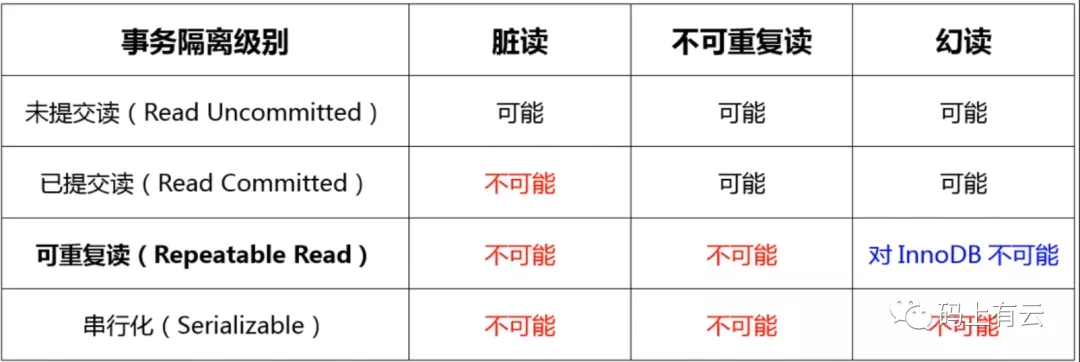
以上隔离级别是如何实现?
第一种方案:
加锁。在读取数据前,对数据进行加锁,阻止其他的事务对其进行操作。(LBCC:Lock Based Concurrency Control)
第二种方案:
生成一个数据请求时间点的一致性数据快照(snapshot),并用这个快照来提供一定级别的(语句级或者事务级)的一致性读取。(MVCC:Multi Version Concurrency Control) 这种方案只在RC和RR 中使用。
首先MVCC 的大致实现原理:
他的宗旨就是创建多个版本的数据,然后对多个版本的数据进行修改查询,从而实现事务的隔离性。
实现MVCC需要的条件:
- 事务需要被记录版本号(即事务的ID:DB_TRX_ID)在数据库表中以隐藏列的形式存在。
- 数据库表的聚集索引列ID(DB_ROW_ID)。
- 数据库表中另外的隐藏列:DB_ROLL_PTR 是指向undo Log的指针。
- undo Log(记录数据被修改之前的日志,数据被修改时会把之前的数据拷贝到undolog,当数据进行回滚时,就根据undolog中的数据进行回滚)。
- Read View(可以理解为维护的一个活跃事务ID的列表)。
开启一个事务A:会产生一个事务的ID号,同时会在readview中维护当前活跃事务的ID,DB_ROLL_PTR 指针指向事务开启之前的数据的undo Log的地址,事务A的操作始终是在当前记录的undo Log 的那些数据中记性操作,如果有其他的事务对数据操作也会指向一个undo Log的指针,操作他的undo Log的数据,所以事务之间的操作并不会影响。
什么是锁
锁是计算机协调多个进程和线程并发访问某一资源的一种机制,锁使用独占的方式来保证在只有一个版本的情况下事务之间的隔离,所以锁可以理解为单版本控制。
引入锁之后就可以支持并行处理事务,如果事务之间涉及到相同的数据时,会使用排它锁,或者叫互斥锁,先进入的事务独占数据之后,其他的事务被阻塞,等待前面的事务被释放。
锁的分类
mysql的存储引擎 InnoDB 既支持行锁也支持表锁,MyISAM 只支持表锁。
从锁的粒度分:表级锁、行级锁、页级锁。
MyISAm引擎在执行查询语句之前,会自动给涉及的表加上读锁,在执行增删改之前会自动给表加上写锁。
简而言之读锁会阻塞写而不会阻塞读,而写锁会将读和写全部阻塞。
行锁与表锁的区别:
锁定的粒度:表锁 > 行锁
加锁的效率:表锁 > 行锁
冲突的概率:表锁 > 行锁
并发的性能:表锁 < 行锁
表级锁:
应用在MyISAM、InnoDB 存储引擎中,但偏向MyISAM引擎,开销小,加锁快,无死锁,锁定的粒度大,发生锁冲突的概率大,并发度比较低。偏向于读操作
MySQL的表级锁有两种,一种是表锁,一种是元数据锁。
表锁 (手动加锁)
- Read Lock (加读锁后可以在加读锁,不能加写锁)
- Write Lock (加写锁后不能加读锁和写锁)
元数据锁 (自动加锁)
当对表记录进行操作的时候(增删改查),MySQL会自动给表加上一个元数据读锁。即不能对表结构进行修改。
- DML(对表记录进行操作:增删改)加读锁
- DDL (对表结构进行修改) 加写锁
意向锁:当为行添加一个共享锁的时候,存储引擎会自动在表上加一个意向共享锁,意向排它锁也是一样。他的作用是提升加表锁的效率。
- 意向共享读锁
- 意向排他写锁
1 | # 给book添加写锁 |
表锁分析:
1 | show open tables; |
1 | show status like 'tables%'; |
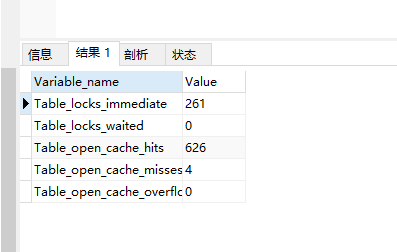
这里有两个状态变量记录MySQL表锁定的情况:
Table_locks_immediate:产生表级锁定的次数。
Table_locks_waited:出现表级锁争用二发生的等待的次数。此值越高说明存在着大量的报表级锁竞争情况。
此外MyISAM引擎,的读写锁调度是写优先,这也是MyISAM引擎不适合用作写操作比较多的情况,因为写锁后,其他的线程不能做任何操作,只能被阻塞。
行级别锁:
是由存储引擎InnoDB实现,行级锁,每次锁住一行数据,锁定的粒度最小,发生锁冲突的概率比较小,并发度比较高。
行级锁从锁定的力度上分为:
Record Lock:(记录锁)锁定单个行记录,对精确匹配或者范围匹配在范围内的数据加锁。RC、RR隔离级别都支持。
Gap Lock:(间隙锁)锁定索引记录间隙,确保索引记录的间隙不变。对范围匹配且符合范围条件但不在范围内的数据也进行加锁。RR隔离级别支持。(防止insert)
Next-key Lock:(临建锁)行锁和间隙锁的组合,同时锁住记录和索引间隙。RR隔离级别支持。
- 共享锁(又称为读锁,S锁) (手动加锁)
select ... lock in sare mode
- 排他锁(又称为写锁,X锁)
- DML(对表记录进行操作:增删改) delete/update/insert 默认加排它锁
select ... for update(当前读)
行锁分析:
1 | show status like 'innodb_row_lock%'; |
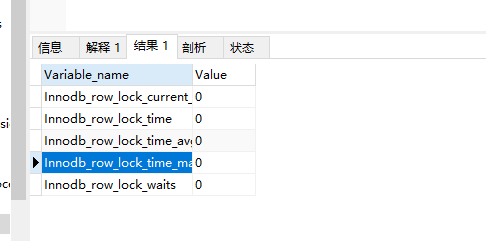
Innodb_row_lock_current_waits:当前正在等待锁定的数量 (比较重要)
Innodb_row_lock_time:从系统启动到现在锁定的总时间长度
Innodb_row_lock_time_avg:每次等待所花的平均时间
Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花的时间
Innodb_row_lock_waits:系统启动后到现在总共等待的次数(比较重要)
页级别锁:
开销和加锁时间介于表锁与行锁之间,会出现死锁,锁定的粒度也是介于表锁与行锁之间,并发度一般。
从锁的操作上来说分为读锁和写锁。
- 读锁:针对同一份数据,多个读操作可以同时进行而不会互相影响。所以也叫作共享锁。
- 写锁:针对同一份数据,当前写操作没有释放锁之前,其他的事务无法对数据进行加锁操作,不管是读锁还是写锁。所以也叫排它锁。
读锁可以让读和读并行,而读和写、写和读、写和写要加排它锁。
从实现方式上分为乐观锁和悲观锁。
锁的使用场景
修改数据库表结构会自动加表级锁。
更新数据未使用索引,行锁会上升到表锁。
更新数据使用索引会使用行锁。
select ... for update 会使用行级别锁。
 微信
微信 支付宝
支付宝


