
Redis底层原理
Redis 数据结构底层实现
String
Redis 是由C实现的,所以Redis的String字符串是由C语言中的String改进而来的。
在C语言中,C的一个字符串是由数组组成的,”sdasd\0”,在C语言中一个字符串是由\0 结尾,但是在Redis中,String类型可以存储任意数据类型,所以使用\0结尾容易发生截断。所以在Redis中实现了一个简单动态字符串 (SDS > simple dynamic string)来存储数据。
SDS :他自定义了一个数据长度来代表数据的长度,在Redis 内部定义了多种 sdshdr5、sdshdr8、sdshdr16。
1 | struct__attribute__ ((__packed__)) sdshdr5{ |
1 | struct__attribute__ ((__packed__)) sdshdr8{ |
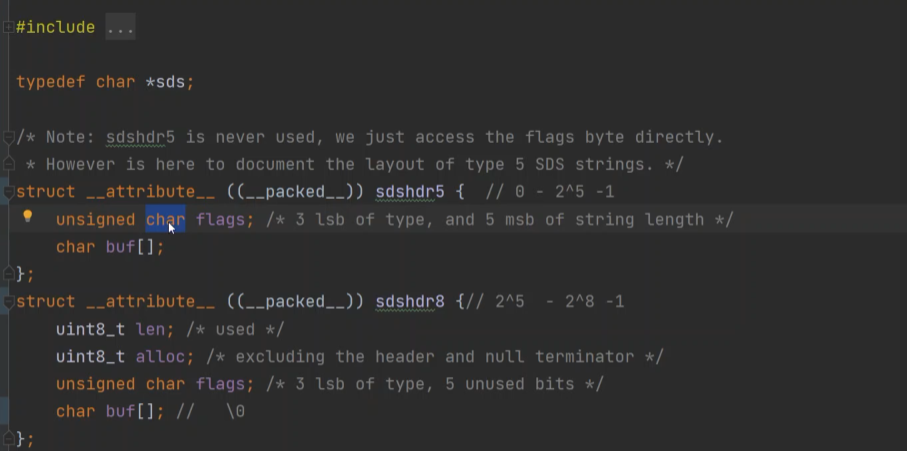

如上图,在底层sdshdr5 是这样定义的:==一个flags 占用一个字节,它又有八bit,前三位表示数据类型,后五位描述数据长度。buffer 是存储的实际数据。==
Redis 数据扩容:内部实现就是将原本的数据长度成倍的扩容,
比如原本的数据长度 len:7
实际的数据长度 buf [5] :”aaaaa”
空闲的数据长度 free:2
现在需要将数据改为 “ aaaaaaaa” 数据长度为8。 那么数据就会变成如下这样:
新的的数据长度 len:7 * 2 = 14
实际的数据长度 buf [8] :”aaaaaaaa”
空闲的数据长度 free:6
所以这样情况下不需要重新分配新内存空间。其中Redis的字符串在复制结束的时候也会自动的加上\0字符,也是为了兼容C语言的一个字符操作的库。
Redis底层数据结构的编码
当我们在使用 set、 hset 、lpush 这些api去设置Redis 的键值的时候,Redis 会根据我们设置的值的不同在内部采用不同的编码格式。当我们在存储一些不同的值的时候,Redis底层也会自动给我们做一些优化。
例如:
1 | 设置 不同长度不同类型的数据 |
1 |
|
1 | 我们在查看他们的类型的时候都是String |
当Value的值小于等于44时,string的编码是 embstr ,大于44是raw。
为什么是44呢?
CPU从内存中拿数据时,是有一个缓存行的概念, 最少的拿的数据长度是64个字节 (64 Byte)。
在Redisobject 中 占了16个字节(16 Byte)
Redis sdshdr8 里面 需要占用4个字节,所以还剩44个字节,Redis为了减少一次缓存IO , 直接将小于等于44 字节的数据取回来 。所以 超过44个字节就会存储为raw编码。
1 | hash 也有不同的编码格式 |
1 |
|
List
从同一边放同一边出 就是一个栈的数据结构。
1 | 127.0.0.1:6379> lpush llist a b c |
从同一边放另一边出 就是一个类似队列的数据结构。
1 | 127.0.0.1:6379> lpush list1 a b c |
List 的数据结构是一个双端链表 :quicklist 。 在Redis 的底层是一个ziplist 更加紧凑的压缩列表。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,即压缩列表。他将所有的元素紧挨着一块存储,分配的是一块连续的内存。
当数据量比较多的时候,才会改为quicklist,因为普通的链表需要的附加的指针空间更大,会比较浪费空间。
比如列表里面存储的只是Int的类型的数据,结构上还需要两个额外的指针:prev和next。
Redis 将链表和ziplist结合起来组成了quicklist,也就是将多个ziplist 使用双向指针串起来,这样既满足了插入删除性能,又不会出现太大的空间冗余。如上图所示。
set
是一种无序、自动去重的的数据结构(如果是一些整形数(编码为intset),其实是有序的)。
他的底层实现是一个value为null的字典,当数据是整形的时候,set集合会将编码改为intset 数据结构,一下两个条件任意满足时set将使用hashtable 存储数据,
- 元素个数大于set-max-intset-entrires
- 元素无法用整形表示
set-max-intset-entrires (intset最大存储的元素个数)最大为512。超过则用hashtable编码。
hash
Hash 类型对应的数据机构有两种:ziplist (压缩列表) 和 hashtable(哈希表) ,当field-value 的长度较短且个数较少的时候,使用ziplist,否则使用hashtable。
hash-max-ziplist-entries 512
ziplist 的元素超过512个 将改为hashtable编码
hash-max-zipl;ist-value 64
单个元素大小超过64个字节的时候将改为hashtable
zset
SortedSet 是Redis的一个特别的数据结构,他的底层使用了两个数据结构 ziplist skiplist。
- 跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素的列表
 微信
微信 支付宝
支付宝



